Microservices, RPCs, SOAP, REST & GraphQL
Jan 22, 2023
Introduction
This article will cover the topic of application programming interfaces, which is an essential unit that makes up the microservice architecture.
The Microservice Architecture.
The micro service architecture is a type of application architecture where the application is broken into several units, communicating effectively with each other over a network protocol. In contrast to monolith applications, which contains the entire logic, client side and server side units in one package that is deployed on a server. On the other hand, the Microservice architecture has its units loosely coupled together, and in most cases distributed across multiple system servers. This is why in many cases, the micro service architecture is referred to as a type of distributed system.
A microservice architecture:

Image Credits: Future Fundamentals
A micro service is not a layer for a monolith application, and has many definitions based on its implementation. Microservices can be characterised by the following factors, as there is no general consensus within the industry that explicitly describes microservices in context. I am merely just trying to make this as intuitive as possible.
- The services are communicated over an internet protocol, particularly HTTP.
- The services could be implemented in several technology stacks and languages.
- It is a collection of individual units implementing a business logic that could integrate seamlessly with other units.
- The components are finely grained and loosely coupled.
- The services could be deployed independently, maintained and managed independently
Practical Example:
I was always confused and not to clear on the microservice architecture. I remember being a tutor for the engineering staff of a government parastatal, where they wanted to migrate their entire infrastructure and codebase to Nodejs, thereby embrace a more loosely coupled architecture than their monolith structured sitting on top of an oracle database. They weren’t clear either. I had to draw up a ton of diagrams to see if they would understand the flow, and I later got the inspiration to break it down into the simplest way possible for one to understand.
Take for example, we have two applications: “Bloglith and Microblog.” I am good at naming things, yes I know. These two applications is essentially a blogging site. You know, where you can post content, people can comment and then people can share, etcetera. Bloglith was built using Laravel, a popular framework based on the PHP programming language, the most popular server side languages powering over seventy percent of the Internet, from Facebook, to Wikipedia and WordPress.
Please note that my choice of Laravel, is to basically explain the monolith system. Laravel is not a monolith framework explicitly — and can be used for building RESTFul APIs in accordance to the microservice architecture. Take note, please.
The application features a MySQL, Maria DB specific database system for storage, Redis for a little caching—PHP code doing the backend jobs, fetching from the database and moving to the client which is basically blade, a templating engine that’s basically HTML. You’ll notice that the only unit that appears detached from the entire flow is the database, which doesn’t matter.
If we were to deploy the Laravel application, all we’d have to do is simply set up a server or instance on let us say, Amazon Web Services, install Ubuntu on it, clone the laravel repository and basically start the app after configuring it for production. We don’t have to bother about any unit individually except our database instance.
So this essentially is a monolith application, and I truly love it! It is intuitive and easy to get up, but in as much as it has its advantages, it could be cumbersome when trying to scale and trying to modify specific portions without the entire app going down in production. Or if there’s a fault, the application would be down in no time. However, we would still compare both architectures later in the article.
Now, for “Microblog.” To demonstrate the microservice architecture, I would be going with the Node JS ecosystem. Nodejs is basically the Browser running as a server environment utilising the Chrome V-8 engine. Our database would basically be Postgres, which is an open sourced relational database, like MySQL, but faster and is used for storing far more complex components. Now, we build out the server side architecture. To do this we initialise a Nodejs based application, running the Express Framework on top. Now we carefully craft out our applications into several units manually, just like we had in Laravel to “models,” “controllers,” and “middleware.” Using a router and HTTP module, we write an implementation to allow the CRUD operations which are Create, Read, Update and Delete happen.
Then we essentially generate a “route” for the application, let’s say for example https://localhost:5000/api/create. Now this is called an “endpoint.” To be more specific an “api endpoint” which a client can consume and access, to create or store a new record in our database. So basically we create the same routes otherwise endpoints for the remaining CRUD operations.
Now, we have set up our backend server, we are missing something—our client! Otherwise the frontend unit of the application. We could simply utilise React here by installing and configuring it independently. Once you have set up React, you could write service handlers to consume the endpoints and represent, otherwise display them to the client. Deployment, as you can see would be far more complex based on building both units individually.
In many cases, we would have to configure our server to allow “cross-origin resources sharing.” CORS is a system that will allow resources on a Web page to be requested and accessed from another domain. In general, this simply means ensuring the browser, otherwise client doesn’t block requests from the server for security policies. After that, you would need to after setting up the database, deploy the server and configure it. Then deploy the client to a different server or host in many cases. Here a reverse proxy comes in, which also servers as an api gateway in many cases. With the microservice architecture, we could have multiple servers, another express server or one in a different stack or language such as Scala, run effectively and all we have to do is make API calls into those endpoints. Amazing, isn’t it? This in a nutshell a practical example a microservice architecture.
Monolith vs Microservice.
There are so many pros and cons of opting for one of these solutions, but it boils down to your needs and preferences.
Monolith Architecture
The pros:
- Fast development time.
- Easy to test.
- Incredibly easy to manage.
- Requires less resources, servers.
- Easy to deploy.
Most applications started off as monoliths before growing into the microservice architecture. So the monolith architecture is obviously a decent starting point for any project.
The cons:
- Scalability issues. Monoliths don’t scale so well.
- It is not flexible.
- It is hard to maintain and troubleshoot.
The last point is very critical, because in many cases you have to take the entire application off the server to work on it, if not it would just stop working. Which is awful.
Microservice Architecture
The pros:
- Improved fault isolation.
- Scales marginally better than the Monolith apps.
- Resusability.
- The ability to incorporate external stacks, languages, tools without breaking the project.
- Continous Delivery and Integration.
- Runs independently so is far more secure and easy to troubleshoot.
- Flexible approaches to the codebase infrastructure.
- Effecrive migrations.
- Interoperability with several technologies.
The cons:
- Difficult to assemble.
- Could be cumbersome to deploy.
- Very complicated.
- Requires extensive knowledge in system design and software architecture, invading distributed systems.
- Maintenance costs are incredibly high.
- Increased complexity.
- Increased development time.
- Overdependence on DevOps tooling.
- Need for distribution, load balancing and other complex techniques for management of traffic and resources.
Microservices, is usually a complicated approach towards building scalable software, and it’s advisable you keep it as easy as possible in the early stages and stick to monoliths, if the application doesn’t require that it should be broken into units and distributed.
What is an API exactly?
Yes, “Api this, Api that.” You’ve probably heard the word api thrown about everywhere, but then you ask yourself, what exactly are APIs? Why are they important? What are APIs actually beyond being abbreviated from the words; application programming interfaces? Well, you would know at the end of this article. An API is simply a unit of the microservice architecture which allows you to share resources from one software platform to another as a service over Internet protocols. Still not clear yet? An example is when we talked about building “Microblog” to illustrate what microservices were. That endpoint, was basically an “API” which our client, another independent piece of software could use to access and share resources! Eureka. Making more sense now? Another instance of an API, is integrating let’s say Stripe into your application to allow payments. That’s basically the meaning of an API.
APIs are very crucial and used in today’s world, to build robust, scalable software applications. We have there types, otherwise categories of APIs, which are used popularly in the world today:
- SOAP based Architecture.
- RPCs.
- REST, my favourite.
Yes, no Graphql. Hold up, GraphQL isn’t explicitly a type of API, but falls under REST and is an alternate option to developing RESTFul APIS, in the same manner that the newboy on the block — tRPC falls under the RPC category. We are going to have a deep dive into these Musketeers of APIs.
1. SOAP Architecture.
I know this brings in thoughts of several bubbly liquids into your mind, but the SOAP architecture is very important and crucial. The Simple Object Acces Control is a protocol that allows distributed units of an application communicate. It was an XML based protocol designed by Microsoft. I know, ew, XML. For those of you reading, XML is a markup language, (Extensible Markup Langauge) utilised not just for APIs, but as the descriptive metadata format of applications. It was however replaced by JSON (JavaScript Object Notation) the best format which we would get into. XML is far more verbose and is the only option implemented by the SOAP architecture, in contrast to JSON which is loose and based on the data.
Diagram of SOAP Architecture:
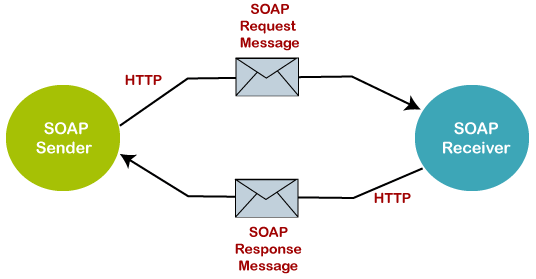
Image Credits: Javatpoint
SOAP supports a variety of transfer protocols. SOAP allows for messaging via TCP (Transaction Control Protocol), a low-level data exchange method that works between ports via an IP network. You can go for the SMTP (Simple Mail Transfer Protocol) option, which is a communication protocol for electronic mail transmission, FTP (File Transfer Protocol), and any other transfer method that supports text data exchange.
Although it only makes sense to use SOAP over the HTTP (Hyper-Text Transfer Protocol) for rare cases and Exceptions it could work over the aforementioned protocols. The components of SOAP include Envelope, Body, Header and Fault.
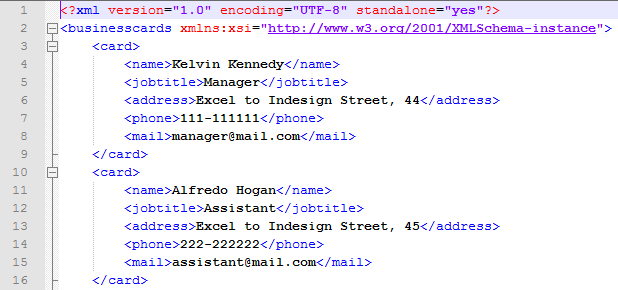
The above code snippet is an implementation of XML in SOAP.
This is my issue with SOAP. JSON is much better and much more focused on the data like so:
{
"name": "emmanuel",
"Lname": "noble"
}
Components of SOAP:
The Envelope tag begins and ends every message, like in HTML.
The Body contains the request or response.
The Header has a message which must determine any specifics or extra requirements.
The fault which informs of any errors that can occur throughout the request processing.
SOAP is quite more primitive and not used extensively anymore since the advent of RPCs and REST. But let us have a view of the pros and cons.
The pros:
- Built in error handling.
- Better Security Extensions.
- Language agnostic.
- Supports so many transport protocols.
The cons:
- Only supports XML that’s a bummer.
- Heavyweight.
- Specialised domain knowledge.
2. RPC Architecture.
One of my favourites. The remote procedural call is an architecture for microservices and complex distributed systems that has been around for quite a long while — I mean, the 1980.
The Initial XML-RPC system was quite cumbersome because ensuring the data types of XML payloads is difficult. Later on an RPC API started using a more concrete JSON-RPC specification which is considered a simpler and straightforward alternative to SOAP.
Diagram of an RPC Architecture:
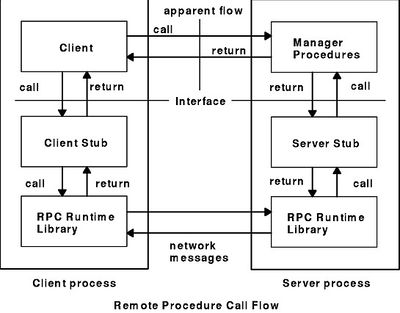
In the RPC Architecture, the client makes a procedure call to send data to the server. When the data arrives in a packet, then the server calls a dispatch routine, and then performs whatever service is requested, and sends a response back to the client. The procedure call then returns to the client. In simple terms this is quite straightforward. A communication protocol used to request data from another computer program within another machine in most cases.
Image Credits: Research Gate.
The pros
- Very high performance.
- Easy to implement functions in the architecture.
The cons
- Not easily discoverable
- Underlying complexity in coupling the api.
The RPC method is used my companies such as Facebook as well, within their massive internal systems which require effecfive communication between each other. Examples of RPC you can read about, is Google’s implementation called “gRPC” and infact—the newest boy on the block which is technically a type safe, library called tRPC for Typescript.
There is a difference between “RPCs’” and “APIs.” One being that RPCs are a communication protocol, whereas an API is used to share resources among clients and servers. The RPC is merely the architecture. So please don’t go out there saying you learnt about “RPC API” from Gray’s Notes.
3. REST Architecture
The Representational State Transfer Architecture, is by far the most used architectural pattern for designing application programming interfaces. It is a communication protocol that relies on HTTP to execute data transfer to a server or client, or access resources from another program.
Diagram of a REST API:
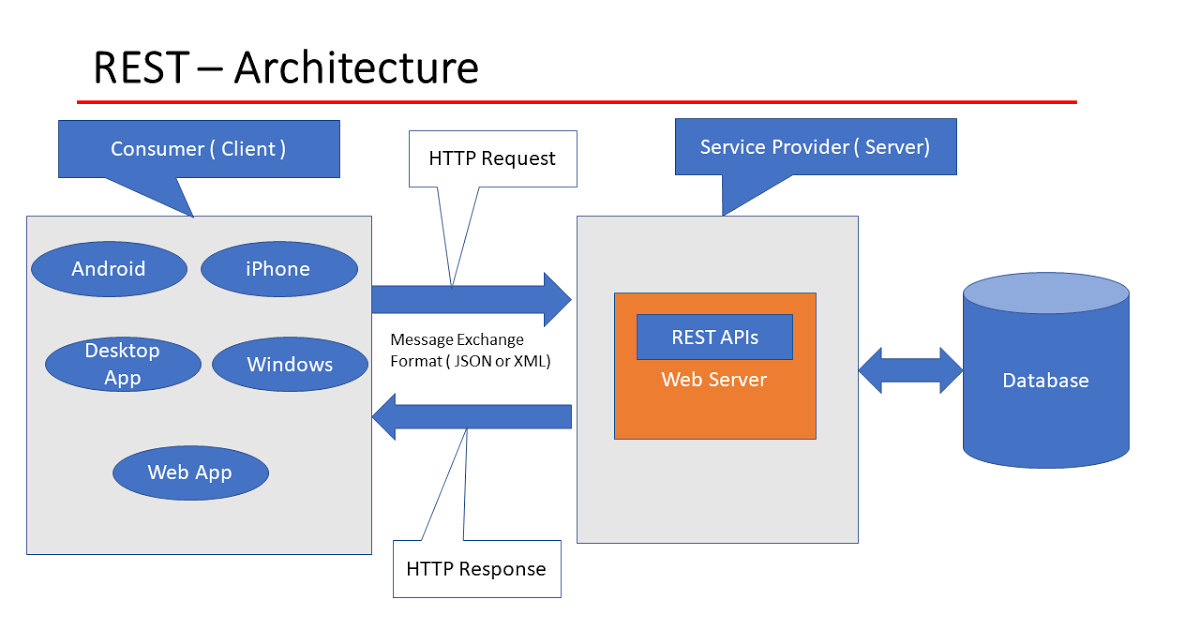
Image Credits: LinkedIn.
This architecture is extremely straightforward forward and had it’s own components as well which we will overview. But let’s get deeper.
A RESTful API implements existing HTTP methodologies defined by the RFC 2616 protocol. These protocols are:
- GET - To retrieve data from a resource.
- PUT - To update data from a resource.
- POST - To store data in a resource.
- DELETE - To delete data in resource.
I actually appreciate this due to the fact that it’s quite more specific than RPC. Employing terms such as “PUT” to differentiate from “POST.”
Here is a practical overview;
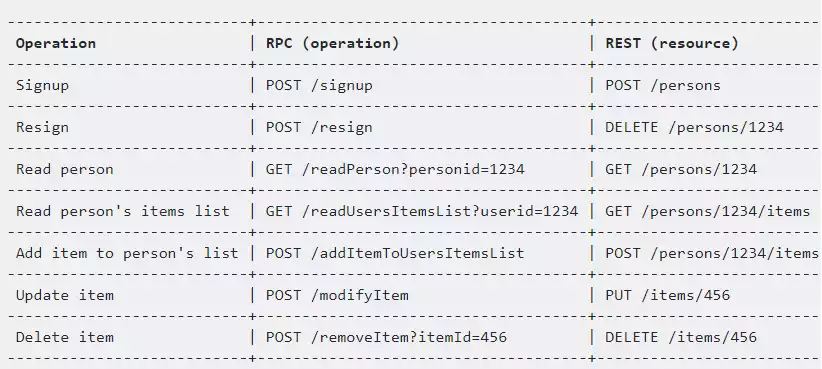
Image Credits: Altexsoft.com.
The REST API is effectively the d’artagnan of the three architectural patterns.
Unlike SOAP, the REST Architecture supports a variety of data formats, with JSON and XML Inclusive.
The REST Architecture also has six architectural constraints it must conform to, in order to regarded as a properly designed REST API and they include and are not limited to:
- Stateless.
- Caching.
- Layered architecture.
- Uniform Interface.
- Provision of Executable Code by the Server.
- Client Server Architecture.
Richardson Maturity Model is a proposed method to achieving truly complete, well designed and useful APIs
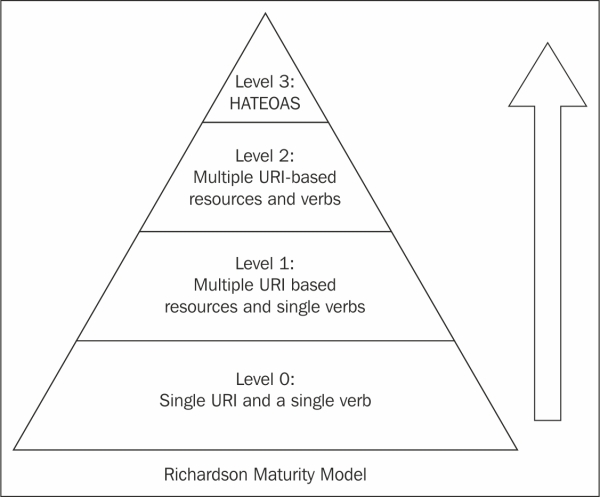
See More: Richardson Maturity Model
If I’m ever, personally building an API—it’s definitely going to be REST.
The Pros:
- Cache Friendly.
- Discoverable.
- Supports Multiple formats as previously mentioned.
- Decoupled Client and server. Remember our example at the beginning of this article, Fren.
The Cons:
- No Single REST Structure
- Over and Under Fetching, very common and frustrating.
- Bigger Payloads.
The REST Architecture could be executed seamlessly through multiple frameworks and languages anyways. That I appreciate, and is the best for resource driven applications.
GraphQL: Son of REST
![]()
“My son, in whom I am well pleased,” is Facebook’s implementation of the REST Architecture using a type based query language, known as GraphQL. So what exactly is GraphQL and what is so special about it?
Well in a nutshell GraphQL is type supportive Syntax that describes how specific data should be obtained from a server or client. Remember the “Overfetching problem?” Ah yes, it makes me want to rip my hair off so bad. GraphQL effectively prevents this and filters the requests to be made. It is also good for implementation in applications with complex data models that reference each other.

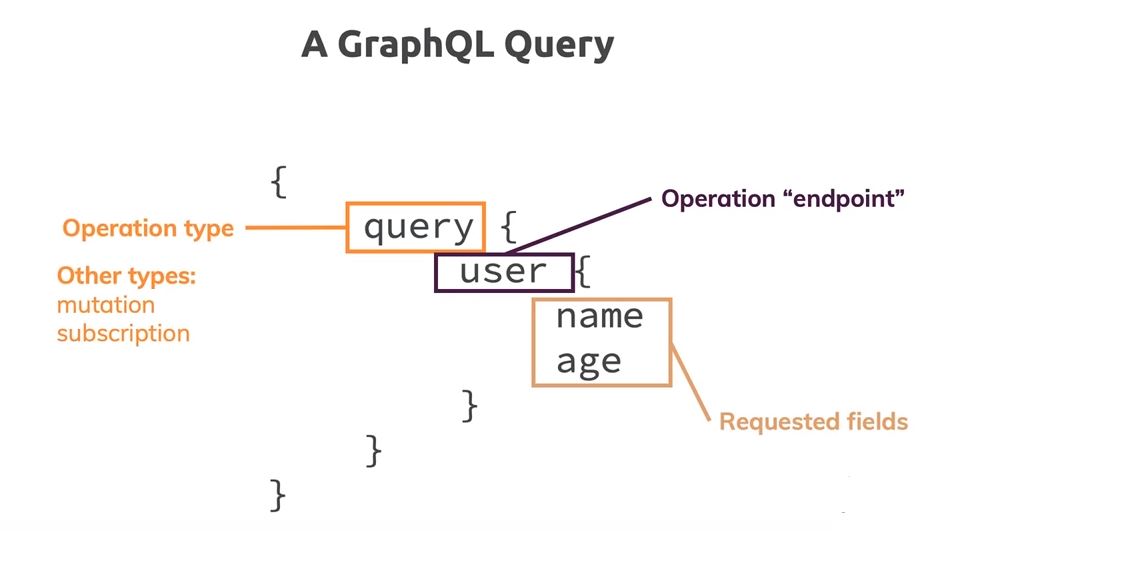
The GraphQL Architecture.
GraphQL starts with building a schema, which is a description ofthe queries you can possibly make in a GraphQL API and all the types that they return.
Having the schema before querying, a client can validate their query against making sure the server will be able to respond to it. On reaching the server side application, a GraphQL operation is interpreted against the entire schema, and resolved with data for the frontend application. Sending one massive query to the server, the API returns a JSON response with exactly the shape of the data we asked for, in contrast to the standard REST HTTP calls.
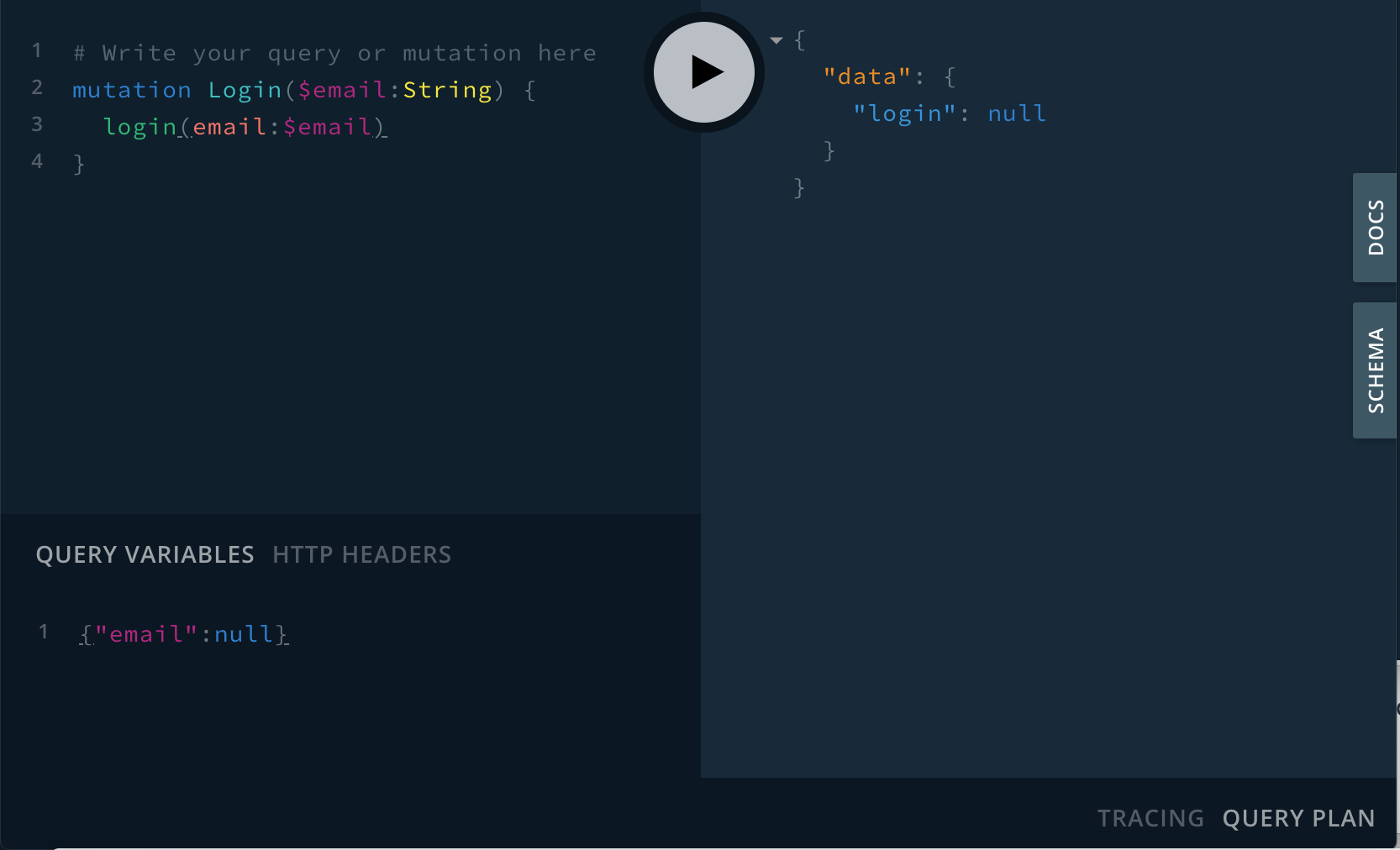
The GraphQL ecosystem is still growing, with libraries such as Apollo supporting it out of the box. It also features a cool environment called the “GraphQL Playground” just like tRPC, for testing—which is pretty cool.
Pros.
- No VERSIONING! You could tell I screamed it.
- Suitable for graph based data.
- Better detailed error messages and response.
- Typed Schema.
The Cons
- Requires custom caching.
- Performance related issues.
Which Musketeer is the best?
Let’s just say REST is preferred by many, but it all depends entirely on your use case, the tools you’re using, your environment and so much more.
Conclusion.
In conclusion, I did not expect this to become a comprehensive article on microservices, the architectural patterns and so many concepts. I’m quite impressed myself. Till the next time we meet, friend.